Summary
Anva is a pipeline / method to create AI animated avatars from a single photo.Contributions
I have done the majority of the software work, while my girlfriend has contributed to the artistic side of the project, including the drawing of certain characters such as Ria.Duration of the Project
On-and-off since 2020.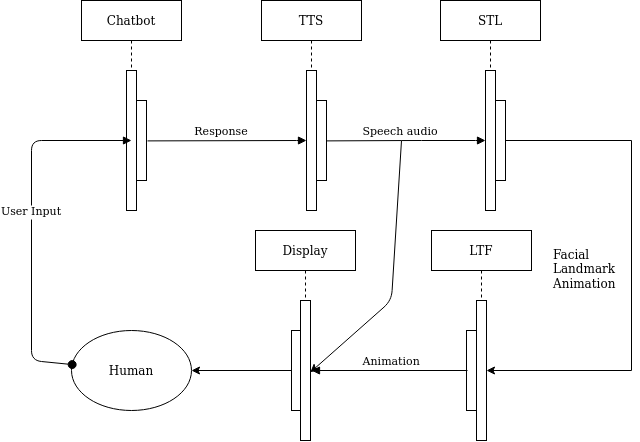
Technical Pipeline
The pipeline of Anva is based on the standard speech to text -> chatbot -> text to speech pipeline. The talking head generation step uses a talking head generator, such as First Order Model (FOM) by Siarohin et al. The exact lipsync and face animation is achieved through driving the FOM model with a 3D model, or a mouth overlapping a driving photo. The lipsync is generated through speech-driven-animation by Vougioukas et al.Historical Characters Come to Life
I initially worked with Humy.ai to explore the potential of using this technology for teaching history. Although the technology piqued interest, the prohibitive inference cost prevented further developments.However, I recently developed a new technique which has resolved this bottleneck.
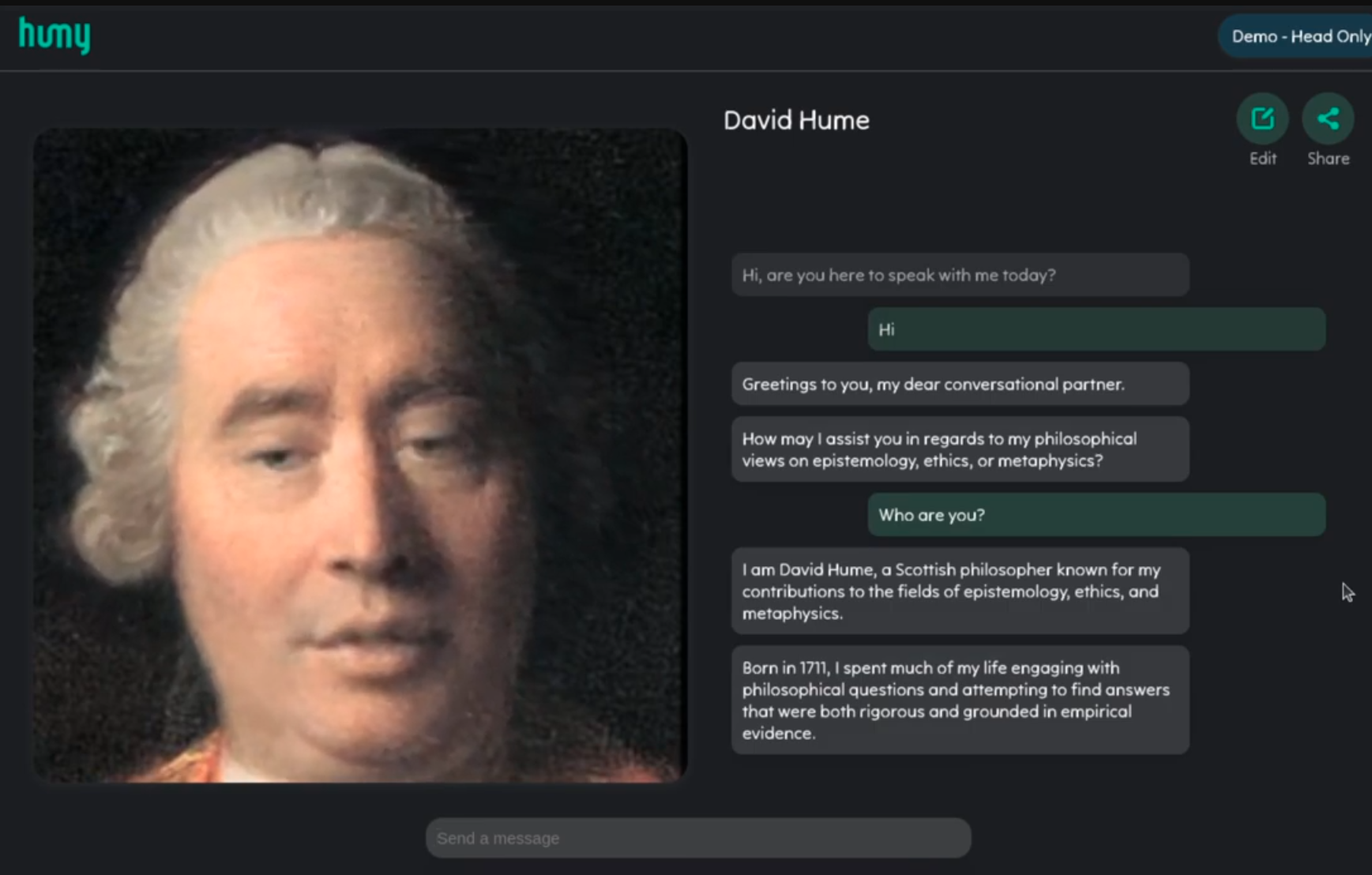

Scalable Inference
To make Anva viable for wide use, I developed a novel technique which reduces the inference cost.The demo video above showcases this process working to allow a 512x512 definition avatar be interacted with in real time through WebRTC, running on a low-tier cloud compute instance. (AWS EC2 c5.large instance - 0.105USD per hour).
Future improvements
Leveraging recent advancements in video animation models, such as X-Portrait-2 and general video diffusion models, it is now possible to generate even more realistic and fluid outputs, including full-body animations.